Our REST API is largely used for retrieval of metadata by machines. But, there are some manual queries that can be performed by you or me to retrieve metadata. Let’s take a look at a common question of the support team from a member looking for information about her colleagues:
I work at the Science State University and I am trying to learn how to use the Crossref API in order to retrieve data about the publications of the researchers of my institution.
In particular, I would like to retrieve the list of the publications of at least one author affiliated to Science State University. Could you please help me with this?
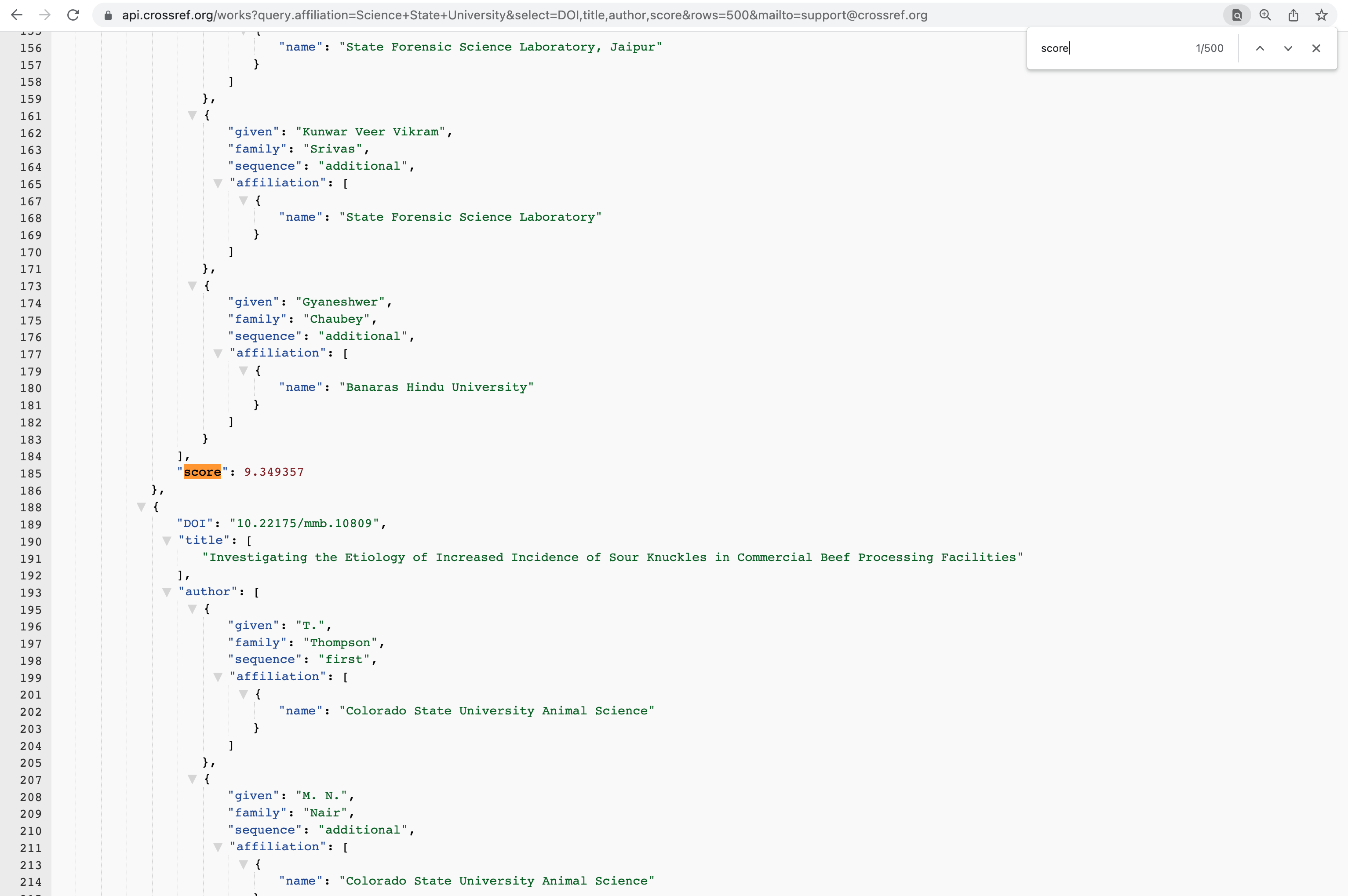
I always like starting with a straightforward query like this: https://0-api-crossref-org.library.alliant.edu/works?query.affiliation=Science+State+University&select=DOI,title,author&rows=500&mailto=support@crossref.org
In this query, I am searching our whole corpus for any affiliation that includes the word Science or State or University; I am limiting the metadata that is returned to me for each DOI to:
- DOI
- title of the work
- the contributor/author list for that DOI
The results are in order of relevance to the query affiliation, so the top results will have a higher match or relevance score for the words Science+State+University than the results down the page. By adding my email address, I can identify myself and thus access the Polite pool of the REST API (you can omit it, if you need to stay anonymous, which will result in querying our Public pool).
Let’s say that I also want the cited-by counts of those same DOIs that I received in my results above. I’d simply add the is-reference-by-count parameter to my query:
We, Crossref staff, keep a list of some of the more useful queries that members and metadata users have sent to or requested of us. I thought it worthwhile to share these with you. You’ll see those below with a brief explanation of the query. It’s also important to note that, if you’re interested in getting started with constructing your own REST API queries, you can use the functionality with our REST API documentation (Swagger) to assist.

Some of the more common REST API query requests we see:
All works on a particular prefix: https://0-api-crossref-org.library.alliant.edu/prefixes/10.35195/works
Article titles on a particular prefix: https://0-api-crossref-org.library.alliant.edu/prefixes/10.35195/works?select=DOI,title
If you want the journal title too, it’s: https://0-api-crossref-org.library.alliant.edu/prefixes/10.35195/works?select=DOI,container-title,title
Which DOIs for a specific prefix have license information deposited for them?
https://0-api-crossref-org.library.alliant.edu/prefixes/10.1098/works?filter=has-license:true&rows=300 (300 results at a time)
All works by title for a prefix:
https://0-api-crossref-org.library.alliant.edu/prefixes/10.21240/works?select=DOI&rows=1000
All works for this ISSN sorted with these elements DOI, title, volume, issue and page number (first 20 results returned):
https://0-api-crossref-org.library.alliant.edu/journals/1527-2095/works?select=DOI,title,volume,issue,page
All works for this ISSN sorted with these elements DOI, title, volume, issue and page number (first 1000 results returned):
https://0-api-crossref-org.library.alliant.edu/journals/1527-2095/works?select=DOI,title,volume,issue,page&rows=1000
All works registered with a specific ORCID iD:
https://0-api-crossref-org.library.alliant.edu/works?filter=orcid:0000-0002-9117-4510
All works registered with a specific ORCID iD with results sorted with only the following metadata: DOI, title, and citation count:
https://0-api-crossref-org.library.alliant.edu/works?filter=orcid:0000-0002-9117-4510&select=DOI,title,is-referenced-by-count
All chapter-level DOIs registered against an ISBN with the results sorted with elements DOI, title, type, container (book-level) title, links, and ISBN:
https://0-api-crossref-org.library.alliant.edu/works?filter=isbn:9783030814649&select=DOI,title,ISBN,type,container-title,link&rows=100
List of DOI counts registered against a prefix and the type of content registered for those DOI counts:
https://0-api-crossref-org.library.alliant.edu/prefixes/10.37670/works?rows=0&facet=type-name:*
What is the most recently deposited DOI that has been indexed in the REST API on a particular prefix Today: https://0-api-crossref-org.library.alliant.edu/prefixes/10.1021/works?filter=from-created-date:2021-05-14,until-created-date:2021-05-14&sort=deposited&order=desc
Overall:
https://api.crossref.org/prefixes/10.1021/works?sort=deposited&order=desc
Show me who is registering grants:
https://0-api-crossref-org.library.alliant.edu/types/grant/works?rows=0&facet=funder-name:*
List of top 10 (and, 1000) most-cited DOIs for a prefix (results limited to DOI, title, and citation count):
https://0-api-crossref-org.library.alliant.edu/prefixes/10.1001/works?sort=is-referenced-by-count&select=DOI,title,is-referenced-by-count&order=desc&rows=10
Works created between two dates:
https://0-api-crossref-org.library.alliant.edu/prefixes/10.31356/works?rows=100&filter=from-created-date:2020-01-01,until-created-date:2020-12-31
All DOIs registered with the isTranslationOf relation: https://0-api-crossref-org.library.alliant.edu/works?filter=relation.type:is-translation-of
I should also note, if you are eager to get started with manual queries and you do not have a JSON formatter installed in the browser of your choice, now might be the time to reconsider that. I use this extension for Google Chrome, but there are other extensions and other browsers, so I encourage you to find one that is right for you: https://chrome.google.com/webstore/detail/json-formatter/bcjindcccaagfpapjjmafapmmgkkhgoa
Let us know what you think. Thanks for reading!
-Isaac